Start at 2016-06-24 11:46:00
First, define topology of a map grid (2016-06-24 11:46:00)...
Second, initialise the codebook matrix (397 X 18) using 'linear' initialisation, given a topology and input data (2016-06-24 11:46:00)...
Third, get training at the rough stage (2016-06-24 11:46:00)...
1 out of 2 (2016-06-24 11:46:00)
updated (2016-06-24 11:46:00)
2 out of 2 (2016-06-24 11:46:00)
updated (2016-06-24 11:46:01)
Fourth, get training at the finetune stage (2016-06-24 11:46:01)...
1 out of 3 (2016-06-24 11:46:01)
updated (2016-06-24 11:46:01)
2 out of 3 (2016-06-24 11:46:01)
updated (2016-06-24 11:46:01)
3 out of 3 (2016-06-24 11:46:01)
updated (2016-06-24 11:46:01)
Next, identify the best-matching hexagon/rectangle for the input data (2016-06-24 11:46:01)...
Finally, append the response data (hits and mqe) into the sMap object (2016-06-24 11:46:02)...
Below are the summaries of the training results:
dimension of input data: 5441x18
xy-dimension of map grid: xdim=23, ydim=23
grid lattice: hexa
grid shape: suprahex
dimension of grid coord: 397x2
initialisation method: linear
dimension of codebook matrix: 397x18
mean quantization error: 0.356873218409639
Below are the details of trainology:
training algorithm: batch
alpha type: invert
training neighborhood kernel: gaussian
trainlength (x input data length): 2 at rough stage; 3 at finetune stage
radius (at rough stage): from 6 to 1.5
radius (at finetune stage): from 1.5 to 1
End at 2016-06-24 11:46:02
Runtime in total is: 2 secs
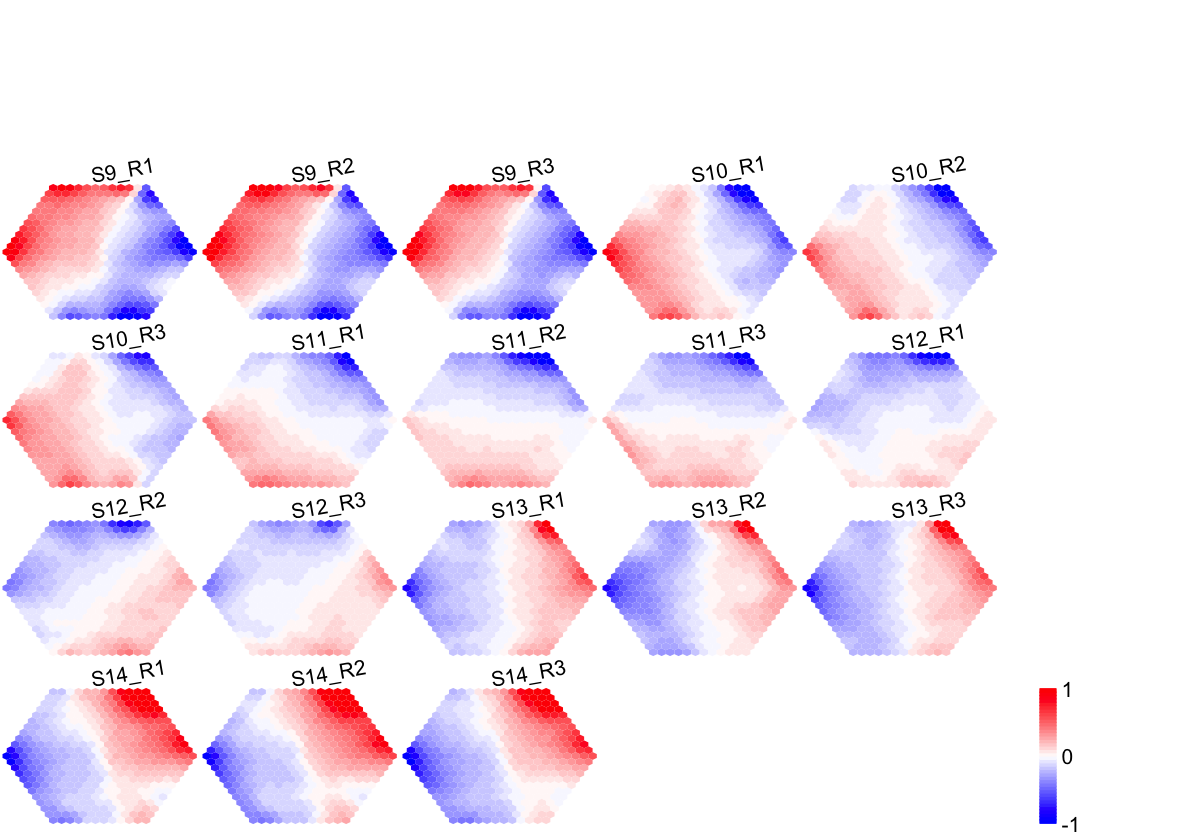
## As you have seen, a figure displays the multiple components of trained map in a sample-specific manner. You also see that a .txt file has been saved in your disk. The output file has 1st column for your input data ID (an integer; otherwise the row names of input data matrix), and 2nd column for the corresponding index of best-matching hexagons (i.e. gene clusters). You can also force the input data to be output; type ?
sWriteData for details.
# (III) Visualise the map, including built-in indexes, data hits/distributions, distance between map nodes, and codebook matrix
visHexMapping(sMap, mappingType="indexes")
## As you have seen, the smaller hexagons in the supra-hexagonal map are indexed as follows: start from the center, and then expand circularly outwards, and for each circle increase in an anti-clock order.
visHexMapping(sMap, mappingType="hits")
## As you have seen, the number represents how many input data vectors are hitting each hexagon, the size of which is proportional to the number of hits.
visHexMapping(sMap, mappingType="dist")
## As you have seen, map distance tells how far each hexagon is away from its neighbors, and the size of each hexagon is proportional to this distance.
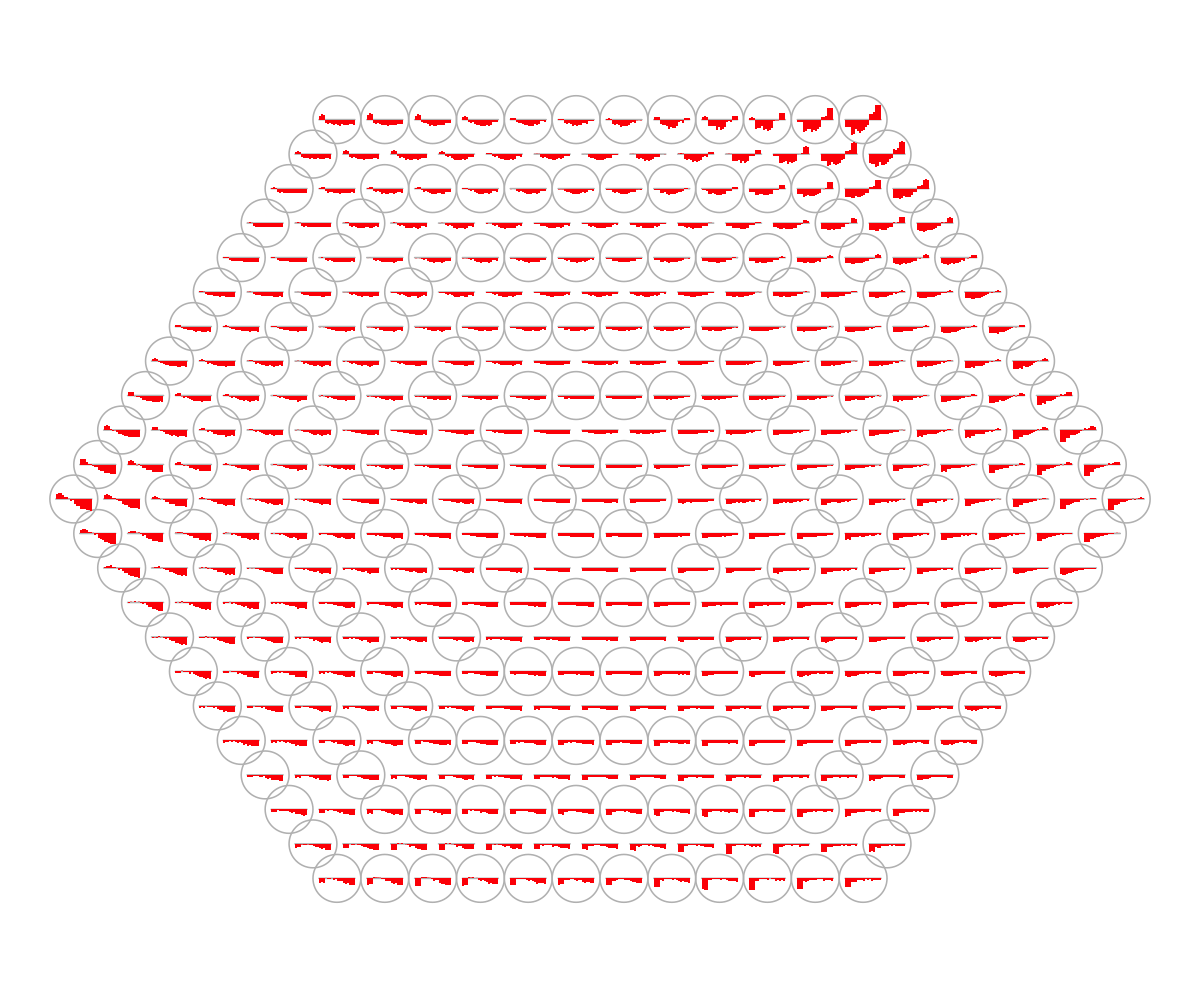
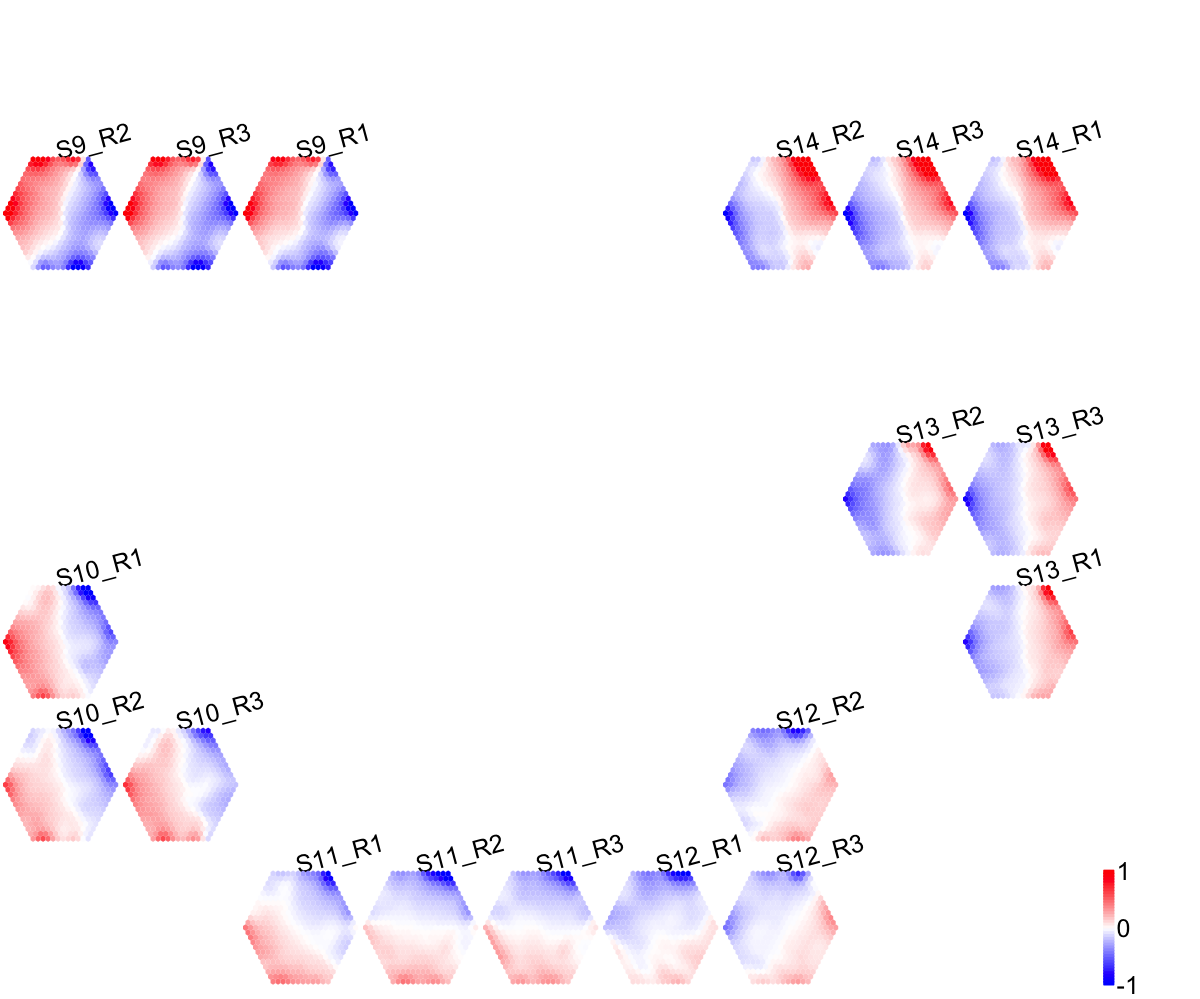
visHexPattern(sMap, plotType="lines")
## As you have seen, line plot displays the patterns associated with the codebook matrix. If multple colors are given, the points are also plotted. When the pattern involves both positive and negative values, zero horizental line is also shown.
visHexPattern(sMap, plotType="bars")
## As you have seen, bar plot displays the patterns associated with the codebook matrix. When the pattern involves both positive and negative values, the zero horizental line is in the middle of the hexagon; otherwise at the top of the hexagon for all negative values, and at the bottom for all positive values.
# (IV) Perform partitioning operation on the map to obtain continuous clusters (i.e. gene meta-clusters) as they are different from gene clusters in an individual map node
sBase <-
sDmatCluster(sMap)
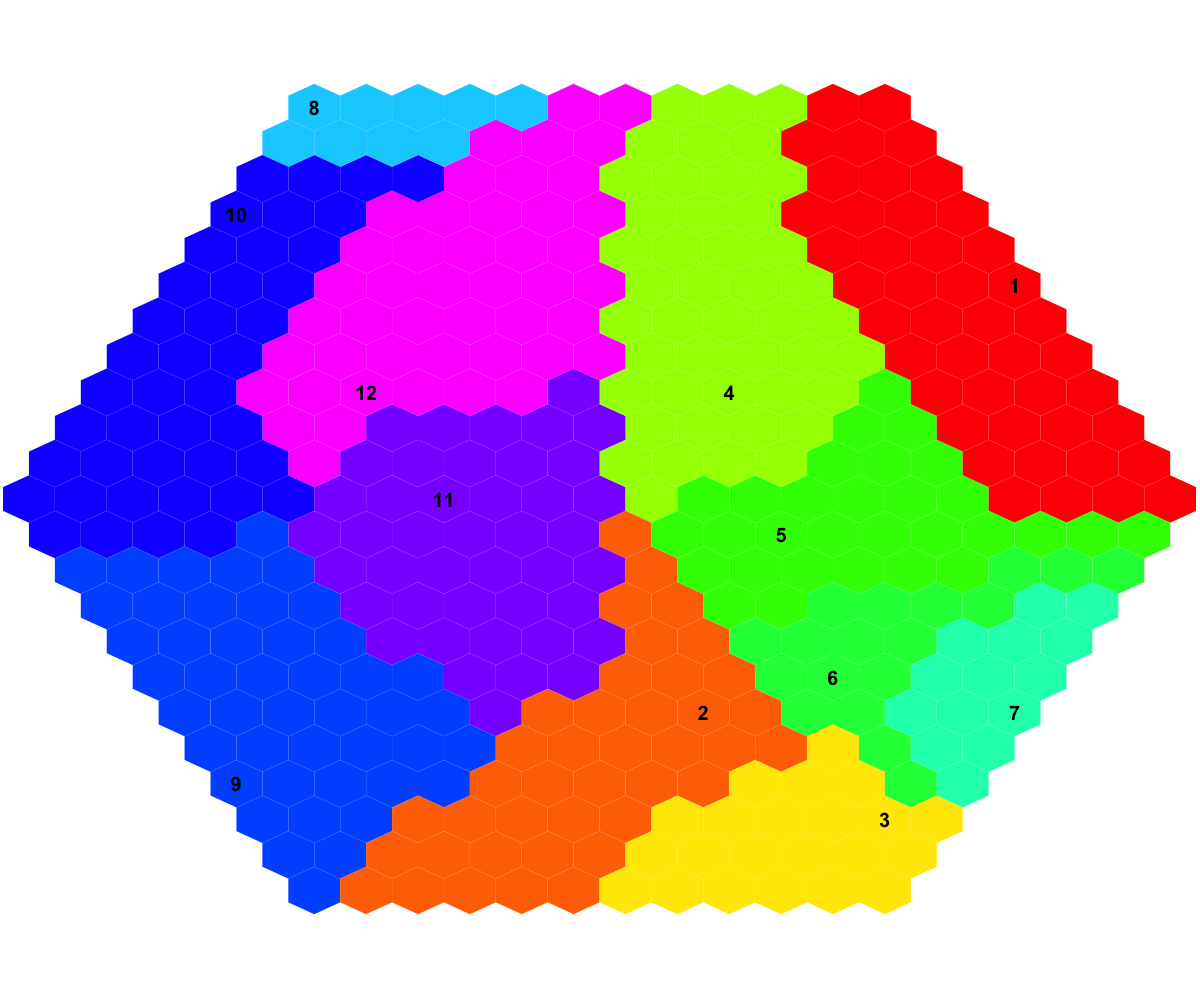
## As you have seen, each cluster is filled with the same continuous color, and the cluster index is marked in the seed node. Although different clusters are coded using different colors (randomly generated), it is unavoidable to have very similar colors filling in neighbouring clusters. In other words, neighbouring clusters are visually indiscernible. In this confusing situation, you can rerun the command
visDmatCluster(sMap, sBase) until neighbouring clusters are indeed filled with very different colors. An output .txt file has been saved in your disk. This file has 1st column for your input data ID (an integer; otherwise the row names of input data matrix), and 2nd column for the corresponding index of best-matching hexagons (i.e. gene clusters), and 3rd column for the cluster bases (i.e. gene meta-clusters). You can also force the input data to be output; type ?sWriteData for details.
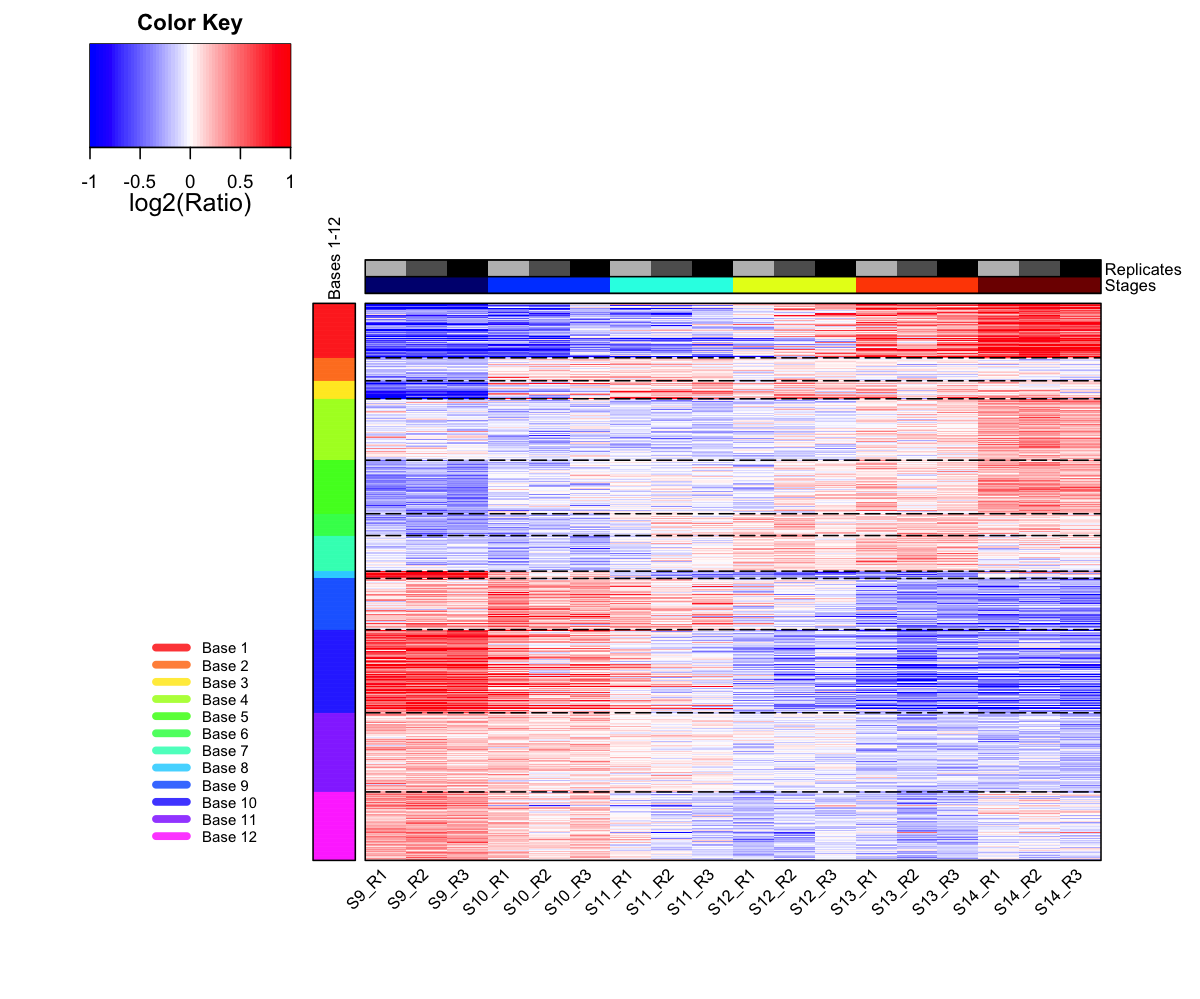
# prepare colors for the column sidebar
# color for stages (S9-S14)
stages <- sub("_.*","",colnames(data))
lvs <- unique(stages)
lvs_color <-
visColormap(colormap="jet")(length(lvs))
col_stages <- sapply(stages, function(x) lvs_color[x==lvs])
# color for replicates (R1-R3)
replicates <- sub(".*_","",colnames(data))
lvs <- unique(replicates)
lvs_color <-
visColormap(colormap="gray-black")(length(lvs))
col_replicates <- sapply(replicates, function(x) lvs_color[x==lvs])
# combine both color vectors
ColSideColors <- cbind(col_stages,col_replicates)
colnames(ColSideColors) <- c("Stages","Replicates")
output <-
visDmatHeatmap(sMap, data, sBase, base.legend.location="bottomleft", reorderRow="hclust", ColSideColors=ColSideColors, KeyValueName="log2(Ratio)", ColSideLabelLocation="right", labRow=NA)
 Start at 2016-06-24 11:46:11
First, define topology of a map grid (2016-06-24 11:46:11)...
Second, initialise the codebook matrix (54 X 18) using 'linear' initialisation, given a topology and input data (2016-06-24 11:46:11)...
Third, get training at the rough stage (2016-06-24 11:46:11)...
1 out of 540 (2016-06-24 11:46:11)
54 out of 540 (2016-06-24 11:46:11)
108 out of 540 (2016-06-24 11:46:11)
162 out of 540 (2016-06-24 11:46:11)
216 out of 540 (2016-06-24 11:46:11)
270 out of 540 (2016-06-24 11:46:11)
324 out of 540 (2016-06-24 11:46:11)
378 out of 540 (2016-06-24 11:46:11)
432 out of 540 (2016-06-24 11:46:11)
486 out of 540 (2016-06-24 11:46:11)
540 out of 540 (2016-06-24 11:46:11)
Fourth, get training at the finetune stage (2016-06-24 11:46:11)...
1 out of 2160 (2016-06-24 11:46:11)
216 out of 2160 (2016-06-24 11:46:11)
432 out of 2160 (2016-06-24 11:46:11)
648 out of 2160 (2016-06-24 11:46:11)
864 out of 2160 (2016-06-24 11:46:11)
1080 out of 2160 (2016-06-24 11:46:11)
1296 out of 2160 (2016-06-24 11:46:11)
1512 out of 2160 (2016-06-24 11:46:11)
1728 out of 2160 (2016-06-24 11:46:11)
1944 out of 2160 (2016-06-24 11:46:12)
2160 out of 2160 (2016-06-24 11:46:12)
Next, identify the best-matching hexagon/rectangle for the input data (2016-06-24 11:46:12)...
Finally, append the response data (hits and mqe) into the sMap object (2016-06-24 11:46:12)...
Below are the summaries of the training results:
dimension of input data: 18x18
xy-dimension of map grid: xdim=9, ydim=6
grid lattice: rect
grid shape: sheet
dimension of grid coord: 54x2
initialisation method: linear
dimension of codebook matrix: 54x18
mean quantization error: 162.781134038408
Below are the details of trainology:
training algorithm: sequential
alpha type: invert
training neighborhood kernel: gaussian
trainlength (x input data length): 30 at rough stage; 120 at finetune stage
radius (at rough stage): from 2 to 1
radius (at finetune stage): from 1 to 1
End at 2016-06-24 11:46:12
Runtime in total is: 1 secs
Start at 2016-06-24 11:46:11
First, define topology of a map grid (2016-06-24 11:46:11)...
Second, initialise the codebook matrix (54 X 18) using 'linear' initialisation, given a topology and input data (2016-06-24 11:46:11)...
Third, get training at the rough stage (2016-06-24 11:46:11)...
1 out of 540 (2016-06-24 11:46:11)
54 out of 540 (2016-06-24 11:46:11)
108 out of 540 (2016-06-24 11:46:11)
162 out of 540 (2016-06-24 11:46:11)
216 out of 540 (2016-06-24 11:46:11)
270 out of 540 (2016-06-24 11:46:11)
324 out of 540 (2016-06-24 11:46:11)
378 out of 540 (2016-06-24 11:46:11)
432 out of 540 (2016-06-24 11:46:11)
486 out of 540 (2016-06-24 11:46:11)
540 out of 540 (2016-06-24 11:46:11)
Fourth, get training at the finetune stage (2016-06-24 11:46:11)...
1 out of 2160 (2016-06-24 11:46:11)
216 out of 2160 (2016-06-24 11:46:11)
432 out of 2160 (2016-06-24 11:46:11)
648 out of 2160 (2016-06-24 11:46:11)
864 out of 2160 (2016-06-24 11:46:11)
1080 out of 2160 (2016-06-24 11:46:11)
1296 out of 2160 (2016-06-24 11:46:11)
1512 out of 2160 (2016-06-24 11:46:11)
1728 out of 2160 (2016-06-24 11:46:11)
1944 out of 2160 (2016-06-24 11:46:12)
2160 out of 2160 (2016-06-24 11:46:12)
Next, identify the best-matching hexagon/rectangle for the input data (2016-06-24 11:46:12)...
Finally, append the response data (hits and mqe) into the sMap object (2016-06-24 11:46:12)...
Below are the summaries of the training results:
dimension of input data: 18x18
xy-dimension of map grid: xdim=9, ydim=6
grid lattice: rect
grid shape: sheet
dimension of grid coord: 54x2
initialisation method: linear
dimension of codebook matrix: 54x18
mean quantization error: 162.781134038408
Below are the details of trainology:
training algorithm: sequential
alpha type: invert
training neighborhood kernel: gaussian
trainlength (x input data length): 30 at rough stage; 120 at finetune stage
radius (at rough stage): from 2 to 1
radius (at finetune stage): from 1 to 1
End at 2016-06-24 11:46:12
Runtime in total is: 1 secs
)
)
)
)
)